一.简介
正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现,再被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行
二.常用字符
1.字符匹配
-
- 元字符
| . | 代指除了换行符以外的任何字符,只能匹配一个字符 | ||||||
| ^ | 匹配行首 | ||||||
| $ | 匹配行尾 | ||||||
| * | 重复匹配0~多次,贪婪匹配 | ||||||
| + | 重复匹配1~多次,至少要匹配一次 | ||||||
| ? | 匹配0次或者一次,可有可无,最多只能有一个 | ||||||
| {} | 精确定匹配次数,或者范围 | ||||||
| [] | 常用来制定一个字符集,如[ab]匹配 a 或b;其他的元字符在[]中不起作用,除了【-】【^】 | ||||||
| | | 或 | ||||||
| () | 分组第一个组号为1 | ||||||
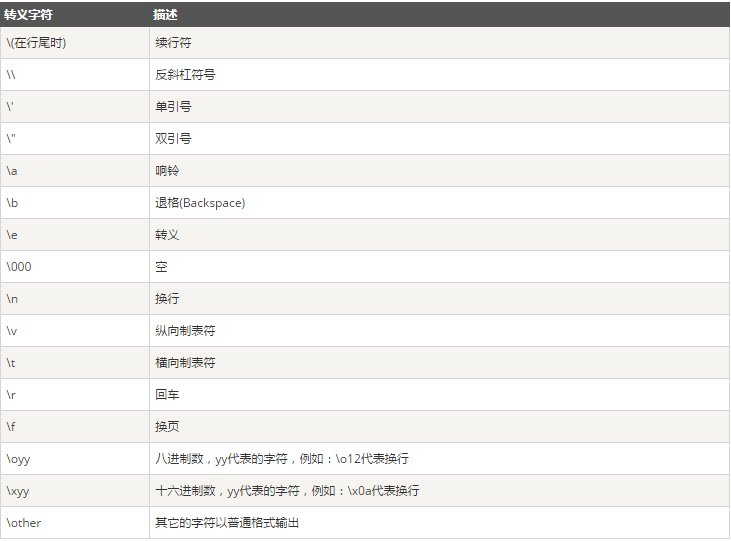
| \ | 转译 | ||||||
反斜杠:
反斜杠后边跟元字符去除特殊功能
反斜杠后边跟普通字符实现特殊功能引用序号对应的字组所匹配的字符串如:
#匹配'c'和'e'中间的任何字符>>> re.findall('c.e','abcdef')['cde']#匹配'c'和’f'之间的任两个字符>>> re.findall('c..f','abcdef')['cdef']#匹配在字符串'ef'之前的一个字符>>> re.findall('.ef','abcdef')['def'] #以'a'开头的字符>>> re.findall('^a','abacd')['a']#以'st'结尾>>> re.findall('st$','test')['st']>>> re.findall('^ac$','abc')[]#以'a'开头‘c'结尾的字符>>> re.findall('^ac$','ac')['ac'] -
-
- 特殊字符
-
| \d | 匹配任何十进制数;它相当于类 [0-9] | ||||||
| \D | 匹配任何非数字字符;它相当于类 [^0-9] | ||||||
| \s | 匹配任何空白字符;它相当于类 [ \t\n\r\f\v] | ||||||
| \S | 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v] | ||||||
| \w | 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_] | ||||||
| \W | 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_] | ||||||
| \b | 匹配一个单词边界,也就是指单词和空格间的位置 | ||||||
import re#匹配获取话号码p = re.compile(r'\d{3}-\d{6}')print(p.findall('010-628888'))#匹配获取网址www = "www.baidu.com"print(re.findall(r'\w+\.\w+\.com',www))#取浮点数print(re.findall(r'\d+(\.\d*)?','num 10.02')) 三.re内置函数
1. match()
作用
决定 RE 是否在字符串刚开始的位置匹配
用法 :
re.match(pattern, string, flags=0)
pattern: 编译时用的表达式字符串。
flags 参数flags用于编译pattern时指定匹配模式,如:是否区分大小写,多行匹配等等。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'
>>> re.match('com', 'comwww.runcomoob').group()'com' #match是以什么开始匹配,加$以什么结果可以达到完全匹配的目的>>> re.match('com$', 'comwww.runcomoob').group()Traceback (most recent call last): File " ", line 1, in AttributeError: 'NoneType' object has no attribute 'group' 2. search()
作用:
扫描字符串,找到这个 RE 匹配的位置
参数:
re.search(pattern, string, flags=0)
一旦匹配成功,就是一个match object 对象,而match object 对象拥有以下方法:
group() 返回被 RE 匹配的字符串start() 返回匹配开始的位置end() 返回匹配结束的位置span() 返回一个元组包含匹配 (开始,结束) 的位置group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。groups()返回一个包含正则表达式中所有小组字符串的元组,从 1 到 所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则
表达式中定义的组。>>> re.search('^a','abcd').group()'a' >>> a = "123abc456">>> re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)'123abc456' >>> re.search(r"(alex)(eric)com\2","alexericcomeric").group()'alexericcomeric'
import rea = "123abc456"re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) 3.findall()
作用:
找到 RE 匹配的所有子串,并把它们作为一个列表返回
参数:
re.findall(pattern, string, flags=0)
>>> p = re.compile(r'\d+')>>> p.findall('one1two2three3four4')['1', '2', '3', '4']
4.finditer()
作用:
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器
找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
参数:
re.finditer(pattern, string, flags=0)
import rep = re.compile(r'\d+')iterator = p.finditer('12 drumm44ers drumming, 11 ... 10 ...')for match in iterator: print(match.group(), match.span())
5.split() 作用:
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割
参数:
re.split(pattern, string[, maxsplit])
>>> p = re.compile(r'\d+')>>> p.split('one1two2three3four4')['one', 'two', 'three', 'four', '']>>> re.split('[a-z]','1a2b3c4d')['1', '2', '3', '4', '']
6.sub()
作用:
使用re替换string中每一个匹配的子串后返回替换后的字符串
用法 :
re.sub(pattern, repl, string, count=0, flags=0)
>>> re.sub('[1-2]','A','123456abcdef')'AA3456abcdef' import re#替换全文空格为[]p = re.compile(r'\s')text = 'test dkjf dkfj'print(p.sub(r'\0',text))def func(m): return m.group(0) + '[' + ']' + m.group(0)print(p.sub(func,text))
7.subn()
作用:
返回替换次数
用法 :
subn(pattern, repl, string, count=0, flags=0)
>>> re.subn('[1-2]','A','123456abcdef')('AA3456abcdef', 2)
8.compile()
作用:
编译正则表达式模式,返回一个对象的模式用法 :
re.compile(pattern, flags=0)
p = re.compile(r'\d+')iterator = p.finditer('12 drumm44ers drumming, 11 ... 10 ...')for match in iterator: match.group() , match.span()
-
re.I 使匹配对大小写不敏感
-
re.L 做本地化识别(locale-aware)匹配
-
re.M 多行匹配,影响 ^ 和 $
-
re.S 使 . 匹配包括换行在内的所有字符
练习:
思路:
1.提取最里层括号内的公式
2.先计算最里层公式内的*/将结果替换到原公式
3.再次循环执行前两步得到结果
计算器
#!/usr/bin/env python# -*- coding:utf-8 -*-import redef final(formula): formula = formula.replace('++','+').replace('+-','-').replace('-+','-').replace('--','+') num = re.findall('[+\-]?\d+\.?\d*',formula) total = 0 for i in num: total += float(i) return totaldef mul_div(formula): while True: ret = re.split('(\d+\.?\d*[*/][\-]?\d+\.?\d*)',formula,1) if len(ret) == 3: ber, cent, aft = ret if '*' in cent: new_cent = re.split('\*',cent) sub_res = float(new_cent[0]) * float(new_cent[1]) formula = ber + str(sub_res) + aft elif '/' in cent: new_cent = re.split('/', cent) sub_res = float(new_cent[0]) / float(new_cent[1]) formula = ber + str(sub_res) + aft else: return final(formula)def calc(formula): while True: val = re.split('\(([^()]+)\)',formula,1) if len(val) == 3: berfor, centent, after = val new_content = mul_div(centent) formula = berfor + str(new_content) + after else: return mul_div(formula)if __name__ == '__main__': formula = "1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))" result = calc(formula) print(result)